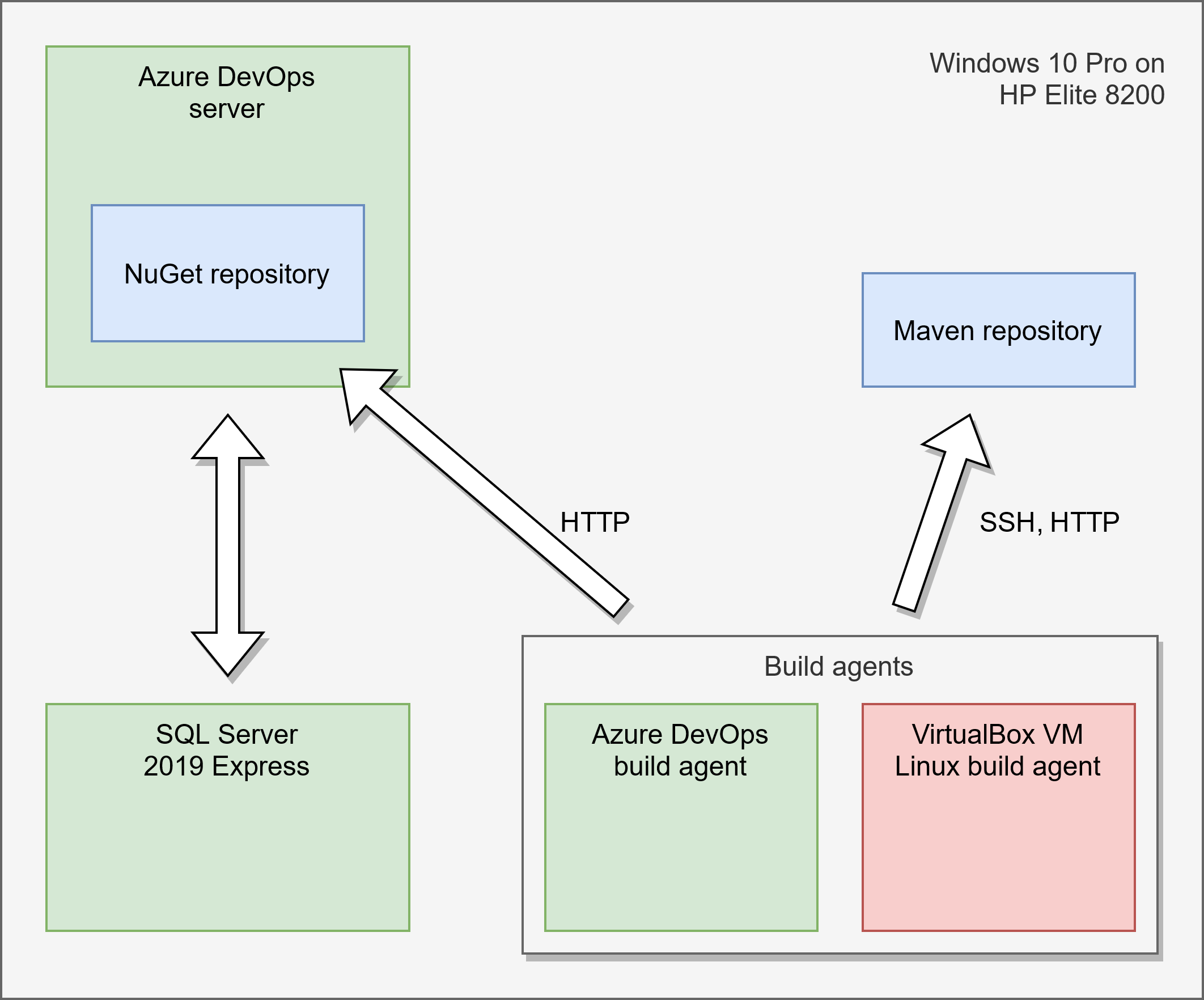
When I first tried to write and run pipelines in GitLab first thing I got were errors. I tried to create a json file containing data that needed to be accessible in each job of the pipeline. This was an id generated randomly in the first step and each following step would rely on this id to produce additional data and store it. I found out, that my generated id file was not accessible in the follow up steps and thus my pipeline would not work. Fortunately there is a solution for this and I’d like to share in a simple example of three files how to make this work. This can be adopted to all sorts of data like binary files, test results, compiler outputs, generated PDFs and all sorts pipeline output. This documented in detail on the official GitLab documentation page but because I prefer quick and direct tutorials handling just my core problem and leave modifications and extensions to me instead of blown up documentations covering every single detail I want to share my solution here.
My solution consists of three files. The first two are the two scripts for the steps. Step one generates the JSON file and stores it and is called “step1.ps1”:
$MyObject = @{
guid = (New-Guid).ToString()
}
$Json = ConvertTo-Json -InputObject $MyObject
Set-Content -Path "guid.json" -Value $Json
Write-Host -Object "Generated Guid: $($MyObject.guid)"The second file is called “step2.json” and reads the generated id from the JSON file and thus needs access to the file “guid.json”:
$Json = ConvertFrom-Json -InputObject (Get-Content -Raw -Path "guid.json")
Write-Host -Object "Loaded Guid is $($Json.guid)"Why is the generated UUID printed to stdout via “Write-Host”? To check if they are the same in the pipeline.
Finally the “.gitlab-ci.yml” file defines the pipeline:
stages:
- create
- read
create-json:
stage: create
script:
- pwsh -File step1.ps1
artifacts:
paths:
- guid.json
read-json:
stage: read
script:
- pwsh -File step2.ps1So now your folder should consist of three files containing the shown code:
And running the pipeline in GitLab will show this:
The jobs can then be opened and should show …
$ pwsh -File step1.ps1
Generated Guid: deb4e6cc-c968-4c86-95f5-fd72ca0f64c9… in the “create-json” job and …
$ pwsh -File step2.ps1
Loaded Guid is deb4e6cc-c968-4c86-95f5-fd72ca0f64c9… in the “read-json” job in the log output.
Now one has the basic principle implemented to share data and artifacts between jobs.
But wait … there’s more!
When opening the job the generated artifacts can be downloaded to the local disk:

This zip file would now contain the file “guid.json” generated by “step1.ps1” and defined in the file “.gitlab-ci.yml” with the lines
artifacts:
paths:
- guid.json