The following script allows you to modify PuTTY sessions in a batch.
Category: Uncategorized
-
Keeping credentials out of your project
Imaging you are working on a project that has database access, API access secured with tokens or uses other credentials that should not be stored in a version control system like git because it would allow everyone with access to get the credentials and access the systems. I’d like to show in a small example how to extract critical and confident information into a protected machine config that is managed by an administration team and how to access this information from the application. For this example I am using a simple Python script that accesses my Azure DevOps environment. I want to give away the generic code but not my internal URL, my collection and project names and for sure not my access credentials. So these files are exported into a file in my home directory which is stored in the defined path “%USERPROFILE%\.goasys\pythonex\credentials.json” (Windows) or “$HOME/.goasys/pythonex/credentials.json” (Linux). This file holds the token, URL and collection and project defintion:
{ "token": "asdf", "url": "https://myserver.local", "localproj": "/MyCol/MyProj" }The generic script, which I could also publish to GitHub for example would then look like this:
import http.client, json, os, platform def read_credentials(): basebath = os.getenv('HOME') if platform.system() == "Windows": basebath = os.getenv('USERPROFILE') f = open(os.path.join(basebath, ".goasys", "pythonex", "credentials.json")) data = json.load(f) f.close() return data if __name__ == "__main__": credentials = read_credentials() conn = http.client.HTTPSConnection(f"{credentials['url']}") payload = '' headers = {"Authorization": f"Basic {credentials['token']}"} conn.request("GET", f"{credentials['localproj']}/_apis/build/builds?api-version=6.0", payload, headers) res = conn.getresponse() data = res.read() print(data.decode("utf-8"))With this method one could also define development, test and production systems and the same application deployed to these systems would use different services and resources. The big advantage is, that the configuration is per machine and the application does not need to be changed and because a generic format is used everything can be stored in this file and the user is not bound to certain predefined fields.
Another use case would be cron jobs running on a server in a certain users context. Other users who can connect to the server should not be able to read the credentials that are used by the service:

As always I hope this helps somebody and makes somebodies lives easier.
-
Migrating commits to open branch
I recently had the problem that I was accidentally working on a local branch that was tracking a protected remote branch. In simple words: I was working on the main branch but was not allowed to push to origin/main. This is a good thing because I see the main branch as stable and I would not want anyone to push directly to main for obvious reasons. So when I started working, not realizing, that I am on the main branch, it looked like this:
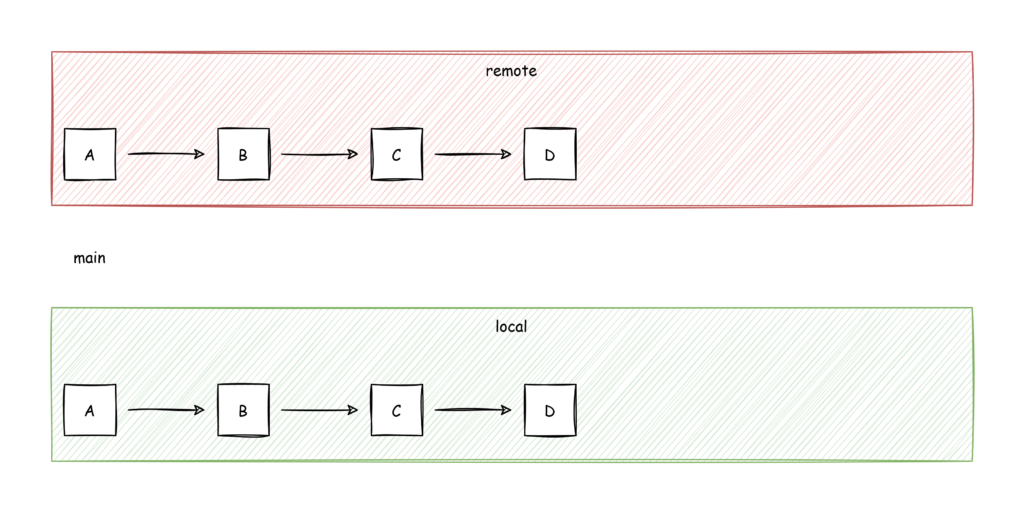
So now I have added some code (on my local main branch) and created a new commit:
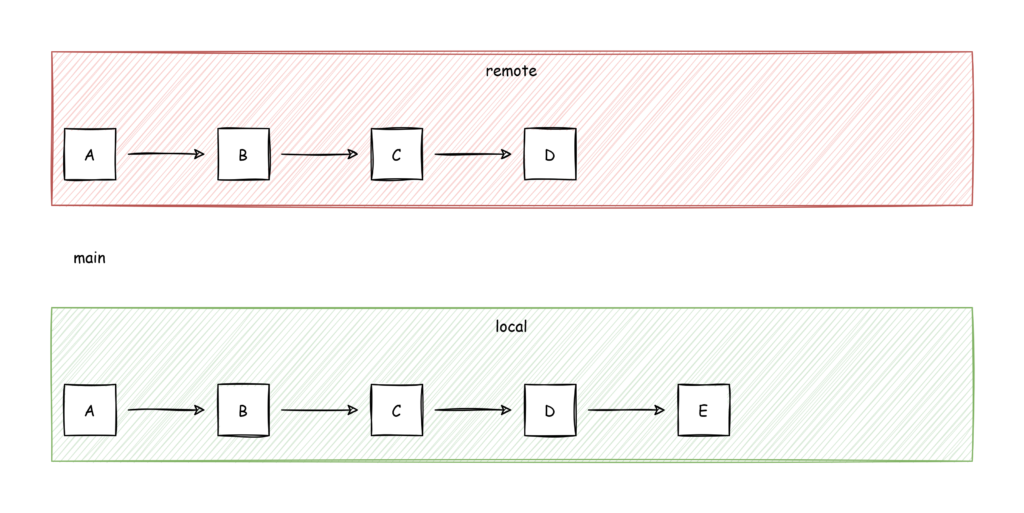
Until this point everything was fine but when I tried
git push origin mainI got the message
PS C:\my.repo.name> git add --all PS C:\my.repo.name> git commit -m "Doing stuff." PS C:\my.repo.name> git push ... ! [remote rejected] main -> main (TF402455: Pushes to this branch are not permitted; you must use a pull request to update this branch.) error: failed to push some refs to 'ssh://my.devops.server:22/MyCollection/MyProject/_git/my.repo.name'Well shit. Now I have my local branch one commit further than my remote and I can’t push them to the remote repository directly. One possibility is to ask the project leader if he would allow me to push to main. Probably he will not. But I found another solution, that worked for me that consists of two steps:
- “Export” the unpushable commit to a new branch and push this branch to integrate afterwards via pull|merge request.
- Reset the main branch to the same level as the remote branch.
The first one is quite easy. Find the commit id with “git log” and create a new branch:
PS C:\my.repo.name> git log commit E (HEAD -> main) Author: AndreasGottardi <andreas@goa.systems> Date: Fri Jun 17 10:39:16 2022 +0200 Adding comment.I have shortened the output. The commit id I used in the example is simply “E” and a real id would look something like “997f11ca98a823aed198df5410f97b769b0b8338”.
With the found id you can create a new branch with
git checkout -b "my/new/branch" ESo basically it looks like this now:
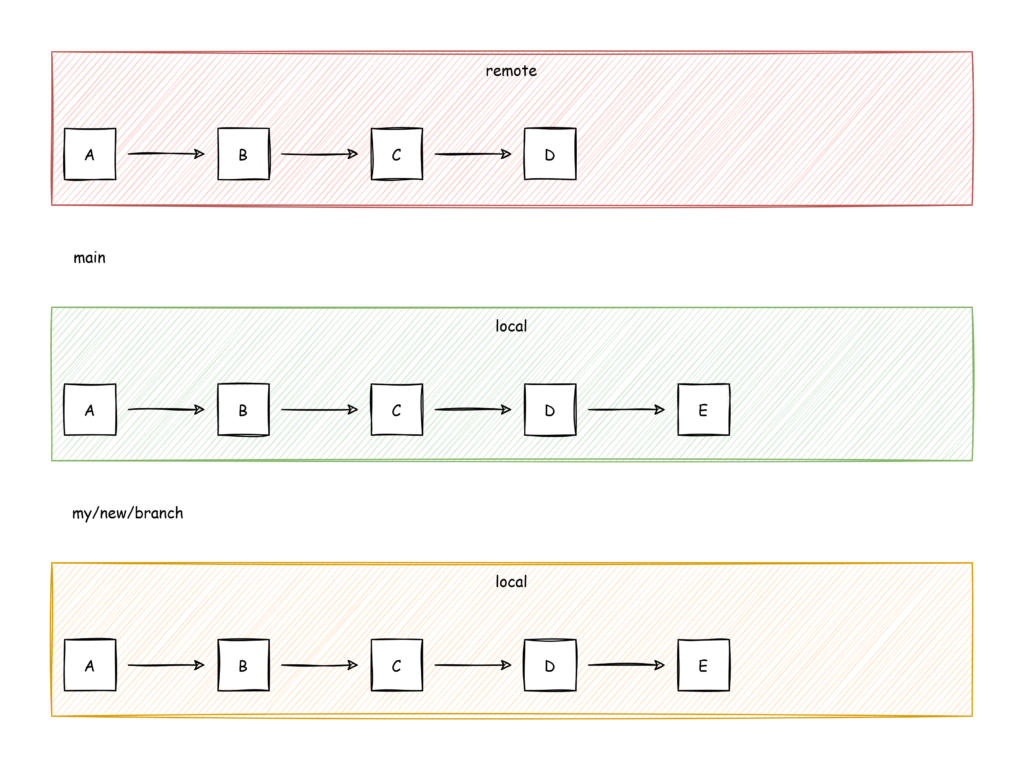
So now you have exported your commit into a pushable branch and you can push it to remote with
git push origin "my/new/branch"From there on it is the regular procedure of creating a pull request and going through the defined review process to integrate it into “main”.
The last step is to checkout main and reset it to the previous commit. Find the ID with “git log” and then reset it with
git reset --hard DNow your local branch “main” is back in sync with the remote branch and as soon as the pull|merge request is through you can pull your changes from the remote branch “main” via
git pull origin main -
Easy PDF form parsing and data handling
Recently I got a employee registration form in “docx” format and I can only assume that after I wrote all my information into the form HR copied it from there into the corresponding system. I thought to myself: That could be done easier. So I wrote a SpringBoot application, that offers a downloadable PDF form where the data can be inserted and this form then can be uploaded to the application and is processed. And by processed I mean the data is taken an converted into JSON, XML and SQL. That’s enough for the scope of the application and shows how easy it is to do something like this.
The project can be found here. It is a regular Gradle project that can be build without any editor support.
gradlew.bat build java -jar build/libs/goa.systems.empman-0.0.1.jarThe page then can be accessed on “http://localhost:8080” and shows this site:
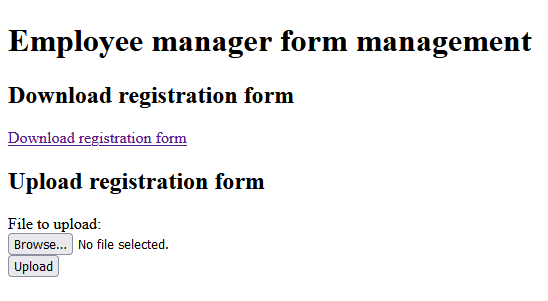
Download the PDF file via “Download registration form”, fill data and save it:
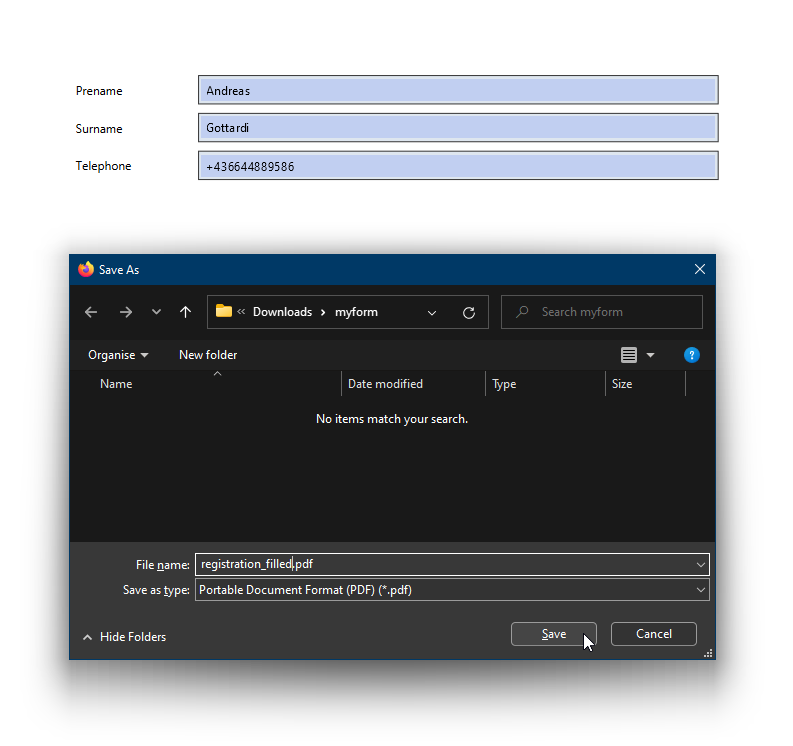
Now choose “Browse…” and select the saved form
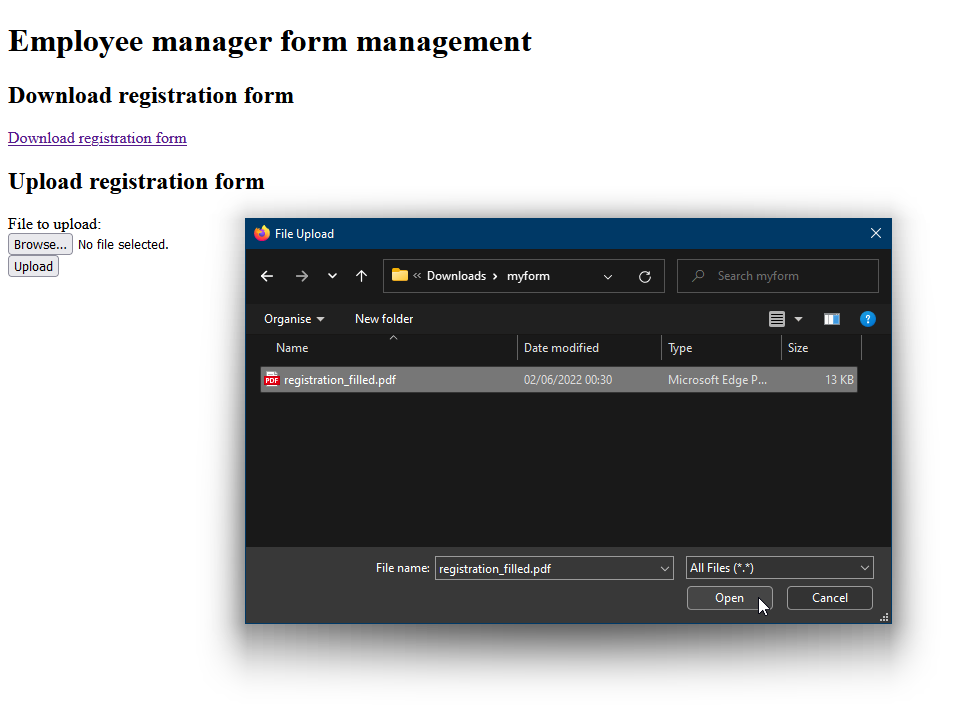
Select “Upload”
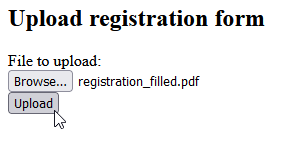
The system will provide a additional validation step to make corrections if something is wrong:
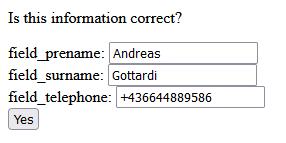
Select “Yes” and the system will now generate a JSON and a XML data structure. Additionally a SQL INSERT command is generated.
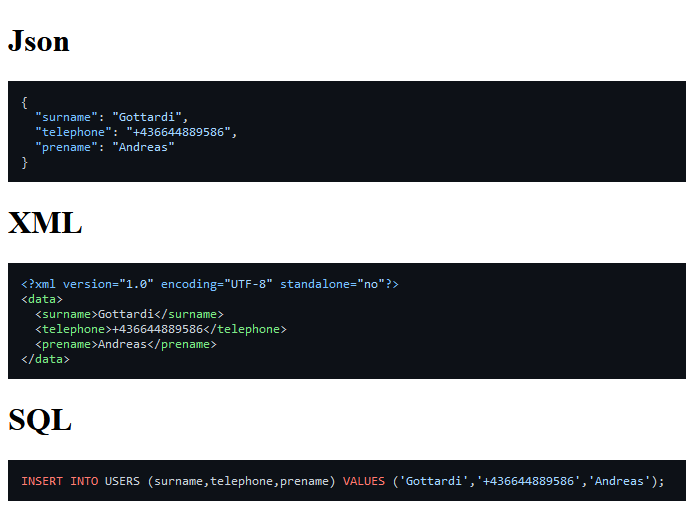
The PDF form was generated with “Libreoffice Writer” following this tutorial. The only convention is, that the text fields must have the prefix “field_”. They look like “field_prename”, “field_surname” and “field_telephone”. The fields are parsed dynamically from the PDF form. So if new fields need to be added, the application does not have to be changed.
-
Apply changes to multiple development branches
Let’s assume you have a simplified agile development process like this one:
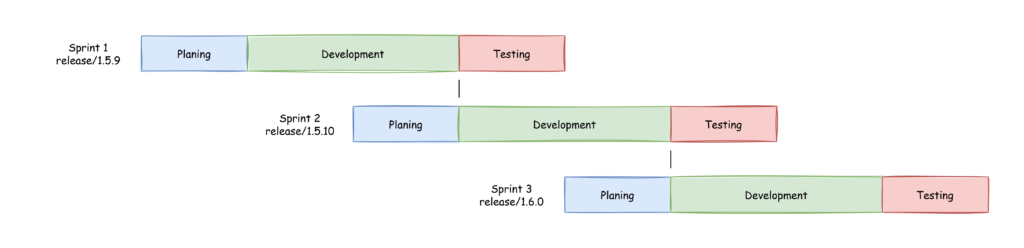
Simple development process During planing the version numbers are specified and during development branches (like “release/1.5.10”) are used to collect all changes developed in development branches (like “bugfix/reference/1.5.10” where “reference” stands for a ticket number, a short description or any other reference to a in depth description). As you can see while the team is developing the second sprint, the first one is tested by the QA department. So what if QA finds a defect? A defect is basically the same as a bug but found by QA instead of the customer and fixed in the same sprint as development took place instead of scheduled into a later sprint. What happens if the defect also has to be fixed in the currently developed sprint? What happens if the code base has changed and it can not be easily applied because method parameters have changed or the code is otherwise incompatible. I know that this is a difficult topic to understand and I tried to visualize it in this article because this saves a lot of time if done right. The only really important thing is, that the team follows the structure and understands why this is done.
To explain this I have expanded the diagram shown above:
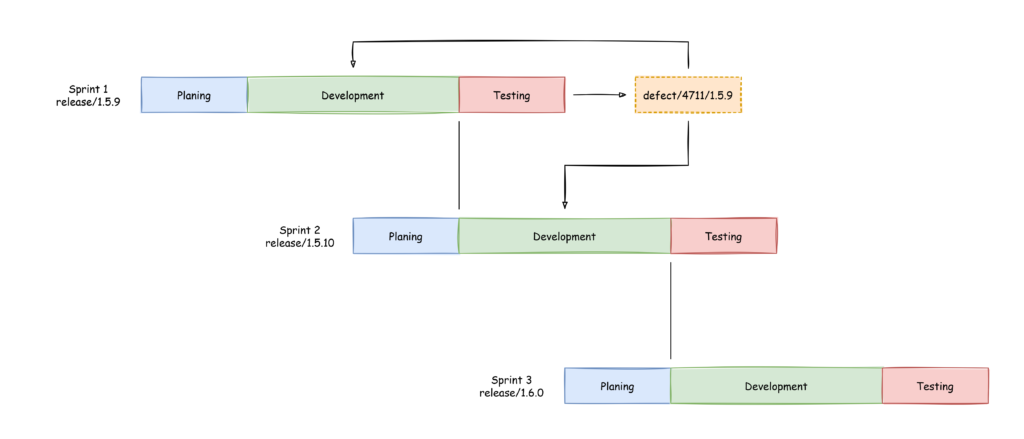
A simple merge The first example is, that the code can easily be applied to the development branch of the next sprint. In GitLab for example when creating a merge request to “release/1.5.9” one can simply disable the deletion of the source branch in the merge request and then additionally create a new merge request to merge it into “release/1.5.10”:

That is the simple case when the code can simply be applied. But what if the code has already changed during development of “release/1.5.10”?
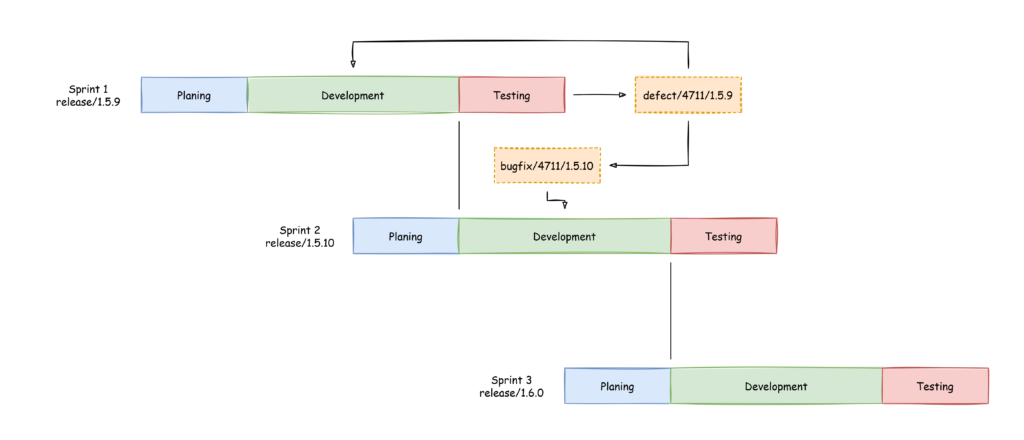
Merging with changes In this example the defect branch is branched again into a bugfix branch for sprint 2. In this new branch changes can be applied to the code to make it compatible to the currently developed version.
This methodology can also be applied if bugs are found in a old version that have to be fixed there and that also have to be applied to later, currently maintained version.
I hope this helps some developers and DevOps engineers out there to reduce headaches and stress during planing and development.
-
Using quotes in remote commands
In my previous tutorial I showed how to escape quotes in Bash and PowerShell commands. So far so good. Now what if you want to execute a Bash command via SSH from a PowerShell instance?
Let’s start with the plain Bash command we want to execute:
echo $'Hello \' world!'
This executed on Bash includes a single quote in the string. Please note the three single quotes in the command. Now to execute ssh on PowerShell on Windows we can use the following command:
PS> ssh ago@server-0003 'YOUR_COMMAND_GOES_HERE'
I spared the actual command in this line to show how this needs to “treated” in order to be executed remotely. Now we know from the previous tutorial that each single quote needs to be replaced with two single quotes in order to be recognized as string character and not as delimiting character. For the shown Bash command this would mean this:
echo $''Hello \'' world!''
Now we can replace “YOUR_COMMAND_GOES_HERE” with the treated command and this would be this:
ssh ago@server-0003 'echo $''Hello\''world!'''

Green: PowerShell, Red: Bash, Selected: Gets replaced with ‘ by PowerShell I hope this helps somebody.
-
Unify line endings
Let’s assume you have a software project and the line endings of the files are inconsistent. Meaning, that git commits and pushes without proper configuration will result in a merge disaster because the merge tools recognize the whole file as changed and not just the lines actually changed. When working on Windows or on a system that supports PowerShell you can use the following piece of code to change the line endings of all files in your project folder:
Get-ChildItem -File -Recurse | ForEach-Object { try { $Content = Get-Content -Raw -Path $_.FullName $Content = $Content.Replace("`r`n", "`n") Set-Content -Path $_.FullName -Value $Content -NoNewline } catch { Write-Host -Object "Error handling file $($_.FullName)" } }This will load the content of each file, replace “\r\n” (Windows line endings) with “\n (Linux line endings) and write the content of the file into the same file it was read from.
-
Archive, compress and send
You want to archive (tar), compress (gzip) and send (scp) a directory in one command? With Linux, it is possible:
tar cf - yourdir | gzip -9 -c | ssh -l root yourhost.example.com 'cat > /path/to/output.tar.gz'What does it do?
tar cf - yourdircreates a uncompressed archive and writes it to standard out (stdout).gzip -9 -creads from standard in (stdin), compresses and writes to standard out.ssh -l root yourhost.example.com 'cat > /path/to/output.tar.gz'takes the content from stdin and writes it to the defined file on the remote host.And the crazy thing: It actually works. Weird shit.
-
Send passwords more secure
Sometimes it is inevitable to send passwords and credentials to a counterpart who needs access to some kind of management tool because there is not extended and secure user management available.
I always just sent the credentials with the login link. Now imagine what this means: A potential scanner or crawler could find my the credentials combined with the login link in one email or if the email gets accidentally forwarded there is also the full information attached including who sent it: Me.
Now I started to use some sort of 2 factor communication:
- Write the credentials in a Zip file and save it with a password.
- Send the protected Zip file via Mail to the counterpart.
- Send the password over a different channel, e.g. WhatsApp, another mail, a phone call or a small piece of paper.
- Do not mention the original Mail with the Zip file in the password message.
What does this mean?
- Somebody unauthorized would not know what the password is for.
- The password for the Zip file (sent via WhatsApp) is in a different system than the Zip file itself (sent via Mail), thus hacking one system does not bring anything.
- The password is not stored in plain text and does not get multiplied by every mail forward.
- This method adds another layer of security because now two systems would need to be compromised.
- It pushes others to also use this system and acts as a reminder to not just forward mails with passwords but to also use the second communication channel because one would have to rewrite or at least edit the mail with the password in order to get everything into one insecure mail.
I got on this topic last time when I received credentials via mail and the password via WhatsApp. In the first moment I took this for granted and realized only a few days later that this is pretty genius. It is not the most secure or absolute perfect solution but it does add a layer of security to communication and this is what security is about for me.
-
Why DevOps?
Why not just developers, like Steve Balmer once said? Why not just managers? Why do you need someone who understands how software is written and who also understands how it can be tested, packaged, deployed and maintained in an automated manner? I think this question answers itself, doesn’t it?
I’d like to bring up an example that I have experienced first hand: Deployment of a PHP based software, developed by an external developer and originally published over a deployment tool provided by the framework developers.
The situation was, that the developers had access to the deployed instances of the software and applied patches manually. This led to the situation that no one knew which patch level was installed on which machine. To be honest it wasn’t even possible to talk about patch levels because hot fixes were applied directly and sometimes not integrated into other installations or the distribution itself. So how do you maintain this? That’s the neat part: You don’t!
So what can you do about this?
1. Draw a line
The development was separated from the deployment and the interface was a versioned zip distribution of the software in the developer to customer direction. Customer to developer direction was implemented as bug tickets and development sprints with a versioned outcome.
2. Split up, define and clean up
All parties, developers, administrators and the DevOps Engineer in between, use the same environments and use the same point of origin: A clean machine with a defined operating system and a clear and not deviating setup procedure. Required manual changes are reported back to the DevOps engineer in order to integrate them into the machine setup process and every one in the team knows how the machines are set up and how they are supposed to work. Log files are in the same location, the same technologies are used on all machines and there are no manual fixes on production instances.
3. Automate
As soon as things are clear: automate. Set up pipelines (in GitLab, Azure DevOps or Jenkins for example), define access (API, SSH or other remote protocols) and specify the installation procedure. This means where to gather your software, what to install, how to configure installed tools and what external sources, like DNS entries and certificates, to use.
Conclusion
The basic tasks of DevOps, like compiling (gcc, javac, csc, tsc …), packaging (Nsis, zip, tar, …), deploying (FTP, SSH, SMB, …), patching and archiving (Maven, NuGet, npm, …) are similar if not the same in most of the cases. One has to know the protocols, how they act together and what it means to “setup” software. A software product is a conglomerate of multiple components: Application, configuration, environment, database and many more things. As a DevOps engineer you have to know that these things exist, that they can be set up and you need the drive to dig into the configuration and not just be satisfied with “yeah it works now”. What drives me is the “How does it work?”, “How is it done in best practice?” and “How can I automate it reproducible?” Yeah, maybe sometimes I invest a little too much time into digging into the topic but I think after 100.000 iteration where my script, I spent a few hours on, works I think it has paid off …