Question: “Do you understand?”
Answer: “Yes!”
Order: “Okay, then implement it.”
Question: “How do I start?”
And that is the difference between understanding something in theory and having experience doing it. There is a lot to it and in this article I’d like to cover this topic on the specific example of creating a repository for your work. I have done this a thousand times and I have a rough idea about naming schema, branching structure and where to put it for which case. What always annoys me is the arrogance and the view, that this is “just a simple task”. 10 different people will name the repositories in 10 different ways. The first with the dot annotation, the second one uses hyphens, the third one camel case, the forth numbers them and so on. This comes from the assumption that “I understand”. And that is just the naming.
It doesn’t matter …
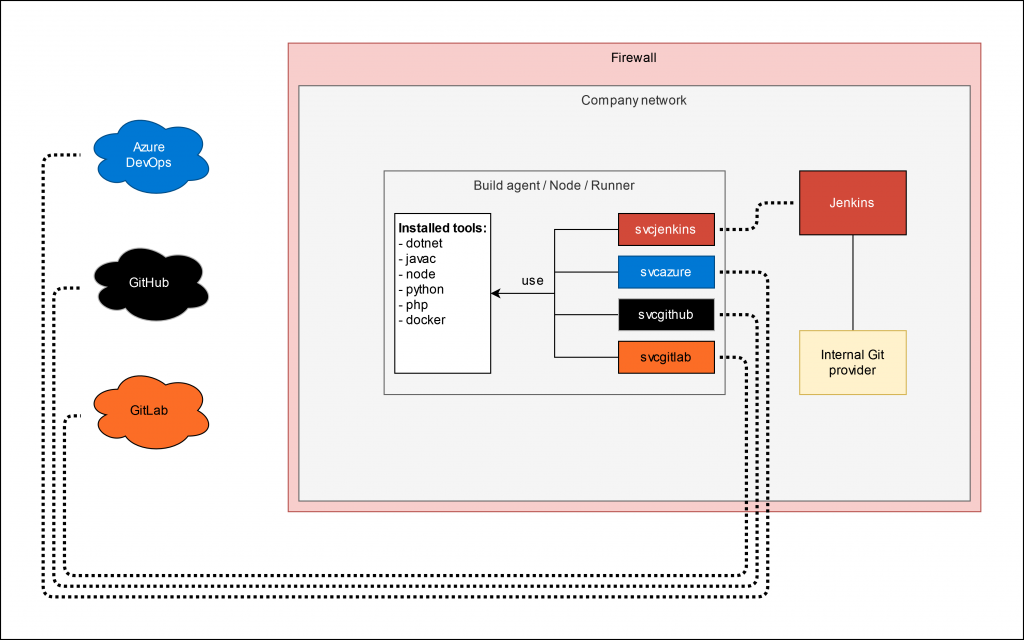
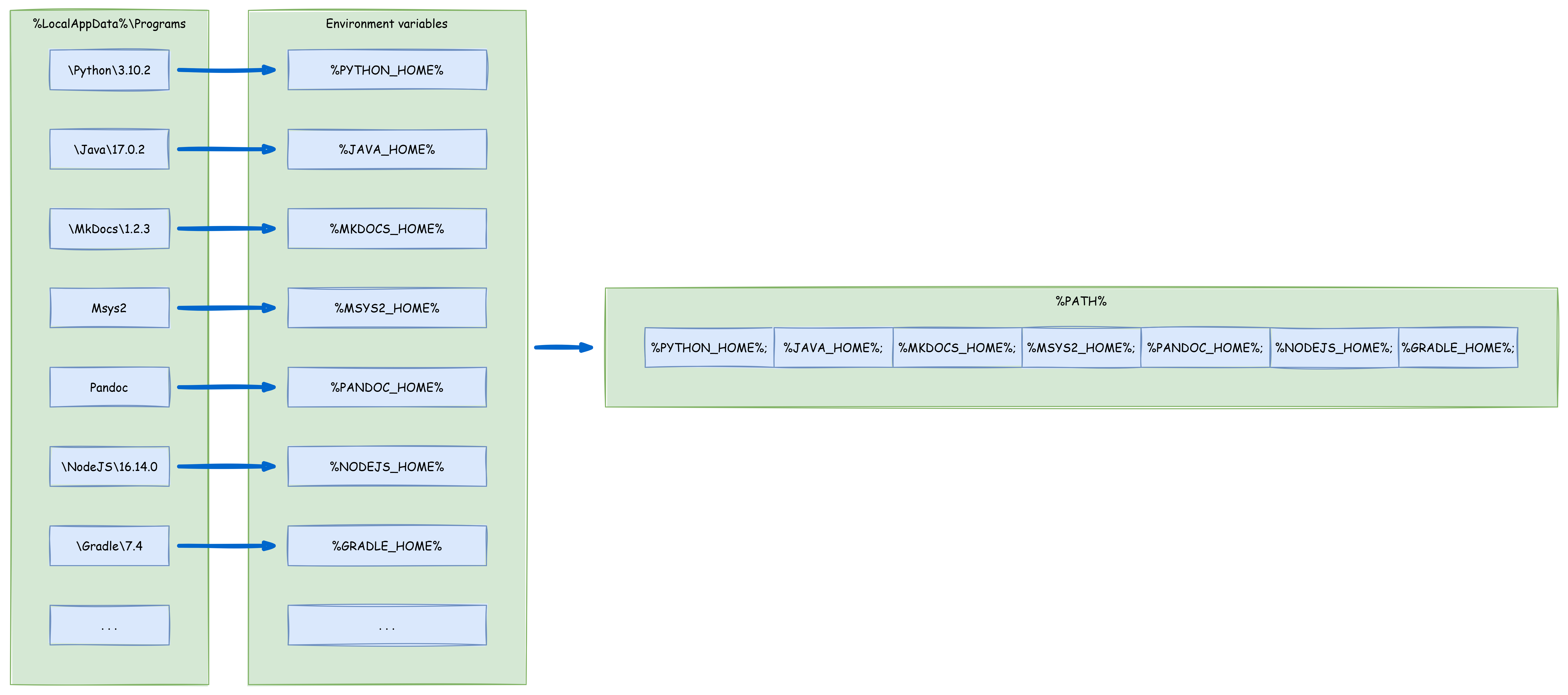
“… it’s just a repository” is often the response when I want to discuss how to name it, what the general schema is and how to set it up correctly. The initial quote might even be correct … if … yeah, if you only have one repository, if you are working alone, if you don’t have to explain it to somebody and if you have a ton of other reasons. But how many successful developers do you know who work alone? See, a recognizable schema, names with a purpose and an easy to search through structure make life much easier. I want to give an example:
“Go to room 80.”
That may make sense if you have one office building with sequentially numbered rooms. But what if …
- … the numbering starts at 1 on every floor and every floor has more than 80 rooms?
- … there is a second office building with the same numbering schema?
- … there are subsidiaries in other locations with the same schema?
- … “Room 80” doesn’t refer to room 80 but to room 0 on the 8th floor?
- … there are more than 10 floors and now you don’t know if, for example, room 180 refers to room 80 on the first or room 0 on the 18th floor.
Context matters. People who spend a lot of time in an environment take it for granted, natural, logic and easy. But in reality, it is not. This is why it is important to talk, share information, discuss and define such things. And no, it is not just a repository. It is a system, a structure and if it is self-explanatory you need less trainings and thus less time and it is less frustrating. This all saves time and as we all know: Time is money.