For certain actions it is required that the Windows Explorer is stopped in order to avoid open file handles or other actions that can be done while the Explorer is running. Windows is configured to restart the Explorer automatically when its process is terminated. I wrote a small PowerShell script that checks the current setting, disables it if necessary, kills the process and then restarts it and optionally restores the setting if it was set in the first place. You can find it here:
This script has to be executed with administrator privileges as it changes values in the system wide part of the registry.
I work with Eclipse a lot and to download a new version, which comes out 4 times a year, I use the following script. It can be executed with PowerShell and does not require Java to be installed on the system because it downloads the OpenJDK version itself. Eclipse can then be found in the folder “eclipse_out” and Java in “java_out”.
Why this script? Because it also installs all the plugins I need. For example “Spring tool suite”, “SonarLint”, “Buildship” and many more.
I use the ssh-keyscan command to get the public keys in order to use the ssh and scp commands without warnings and errors. To generate a list of hosts I feed the IPv4 and IPv6 address and the hostname to a function to generate the command. To format these three values into the string with the command the following code snippet can be used.
I have a bunch of Linux hosts to perform actions on. Updates, certificates, cleanup, you name it. I do all my work over “ssh” but for that to work the hosts must be trusted. Of course I can use “ssh-keyscan” to get the keys but my own “known_hosts” file gets pretty messed up when I add all the keys there. I would like to use a temporary solution. The best would be a parallel temporary solution so that I can handle a lot of hosts at once. Fortunately PowerShell allows such a thing. In this example the host has the name “4ab586fc-9a23-49eb-8d81-f2ca021203aa” (I really love GUIDs) and the full domain name would be “4ab586fc-9a23-49eb-8d81-f2ca021203aa.example.com”. Keeping this in mind the script that gets the key, performs the action (a simple “ls”) and deletes the key would look like this:
The catch here is, that the servers public key is temporary stored in a local file instead of the users “known_hosts” file and then referenced with the parameter “-o UserKnownHostsFile=$Uuid.known_host” in the ssh command. After completion the file is then removed and the access to the server was a success. Running this in a loop allows the execution of tasks on multiple servers at the same time.
Assuming one needs to setup a LAMP server identically to a existing machine and it is important that all the specific packages are installed in order to guarantee a stable execution of the application. the following command prints out a single line list of installed packages for the provided search terms:
This is a short introduction into building applications like Visual Studio solutions, Gradle/Ant/Maven- or Makefile projects.
What does building mean in general?
Transfering your project from one state to another. This means for example one takes the source files and derives binaries from them or creating a pdf documentation from the contained markdown files. Thus build steps for a project can have a lot of functionality. Not only compiling the source code but also executing tests, packaging the software and so on.
How do I do it?
You run one or many applications. The following list gives a short overview over a few types and where to download them.
javac – compiles Java source files into Java classes.
dotnet – does the same for C# source files and much more. This can also build whole solutions.
msbuild – the older sibling of the dotnet command. Builds solution files usually generated by Visual Studio. Can be downloaded separately with the “Build Tools” package.
csc – The C# compiler. msbuild and dotnet include project building functionality whereas “csc” is only the command to compile C# source code files into executables.
As you can see, there are many tools for compiling, building, packaging and executing tasks in the field of software development. What I want to say with this is:
Each action available in an IDE (like Visual Studio, Eclipse, VSCode, Netbeans, IntelliJ, …) is normally also available on the command line and can thus be scripted and executed on a remote system by checking out the repository and executing the necessary commands in the directory.
Why should I script it? I can just run it on my computer in the IDE.
And you are going to ship your computer to the customer or what?
DevOps is basically a summary of processes that handles the different stages of a project like compiling, testing, packaging, generating the documentation, deploying, archiving, etc. These process steps are defined in the project configuration files mentioned above and the tools do that for you. Based on the current setup more or less successful. If msbuild, java or gcc is not available on the system, how should project be compiled then? That’s called prerequisites and they have to be fulfilled.
One good practice is to define a environment for the build script where the tools are defined in the variable PATH to make them generally available. Another would be to define them in the global PATH environment but then there is a chance that they might interfere with other tools on the machine. For example the ESP32 environment also uses a version of gcc but this one is not compatible with the the version that can generate 64bit Windows executables. Thus it makes sense to define the required tools only in the environment they are used in and not globally.
I am writing automated updaters for certain applications but I don’t want the update to be executed every day. Instead it should only run in case a new version is available. One key component to achieve this is to find out what the latest version is. If a software distributor is using GitHub and if the releases are maintained there the versions can be accessed via API. I wrote a small BaSH snippet to parse the latest version string into a BaSH variable. I demonstrate this I am using the repository of a really great piece of software: Kimai time-tracker. This is a time tracking software I also use for my projects, customers and invoices. It features a well maintained documentations, a great API to connect it to 3rd party applications and a more than usable interface!
TAGNAME=$(curl -H "Accept: application/vnd.github+json" https://api.github.com/repos/kevinpapst/kimai2/releases \
| grep tag_name \
| head -1 \
| sed -E 's/^.*"tag_name": "(.*)",$/\1/g')
So what does this code do? It fetches the releases from the API, looks for lines containing “tag_name” (the member that holds the version number), takes only the first line and extracts the value from the line using sed with a regular expression. The output is assigned to the variable “TAGNAME” and can be used for further evaluation.
Imaging you are working on a project that has database access, API access secured with tokens or uses other credentials that should not be stored in a version control system like git because it would allow everyone with access to get the credentials and access the systems. I’d like to show in a small example how to extract critical and confident information into a protected machine config that is managed by an administration team and how to access this information from the application. For this example I am using a simple Python script that accesses my Azure DevOps environment. I want to give away the generic code but not my internal URL, my collection and project names and for sure not my access credentials. So these files are exported into a file in my home directory which is stored in the defined path “%USERPROFILE%\.goasys\pythonex\credentials.json” (Windows) or “$HOME/.goasys/pythonex/credentials.json” (Linux). This file holds the token, URL and collection and project defintion:
The generic script, which I could also publish to GitHub for example would then look like this:
import http.client, json, os, platform
def read_credentials():
basebath = os.getenv('HOME')
if platform.system() == "Windows":
basebath = os.getenv('USERPROFILE')
f = open(os.path.join(basebath, ".goasys", "pythonex", "credentials.json"))
data = json.load(f)
f.close()
return data
if __name__ == "__main__":
credentials = read_credentials()
conn = http.client.HTTPSConnection(f"{credentials['url']}")
payload = ''
headers = {"Authorization": f"Basic {credentials['token']}"}
conn.request("GET", f"{credentials['localproj']}/_apis/build/builds?api-version=6.0", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))
With this method one could also define development, test and production systems and the same application deployed to these systems would use different services and resources. The big advantage is, that the configuration is per machine and the application does not need to be changed and because a generic format is used everything can be stored in this file and the user is not bound to certain predefined fields.
Another use case would be cron jobs running on a server in a certain users context. Other users who can connect to the server should not be able to read the credentials that are used by the service:
As always I hope this helps somebody and makes somebodies lives easier.
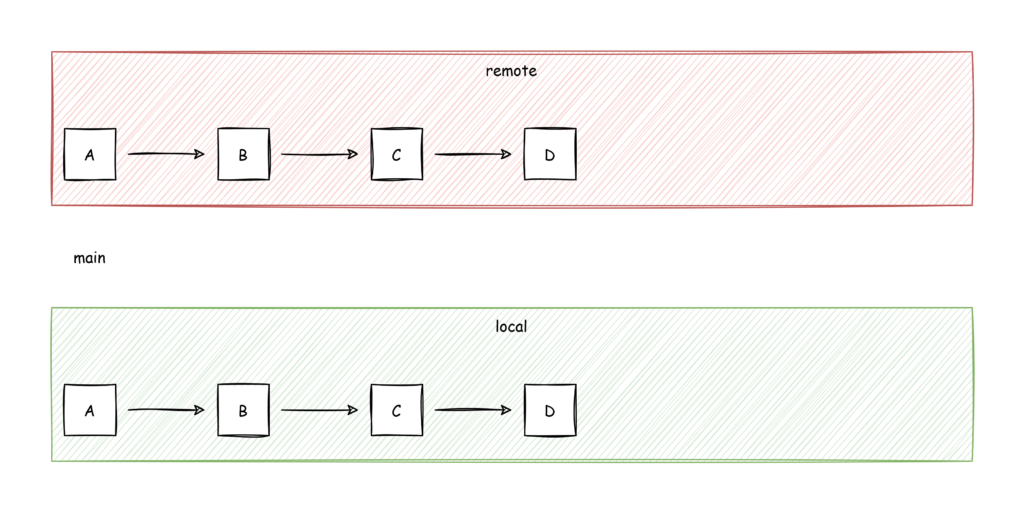
I recently had the problem that I was accidentally working on a local branch that was tracking a protected remote branch. In simple words: I was working on the main branch but was not allowed to push to origin/main. This is a good thing because I see the main branch as stable and I would not want anyone to push directly to main for obvious reasons. So when I started working, not realizing, that I am on the main branch, it looked like this:
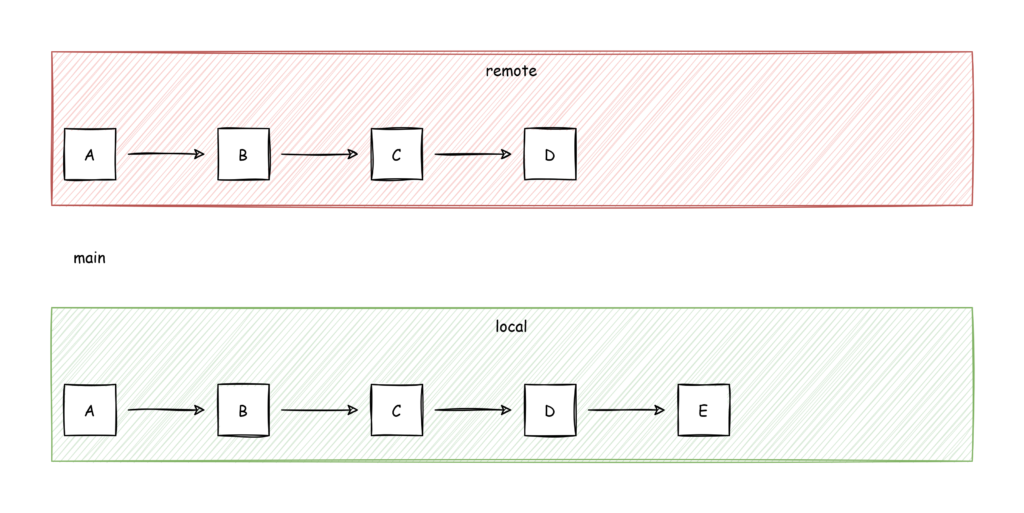
So now I have added some code (on my local main branch) and created a new commit:
Until this point everything was fine but when I tried
git push origin main
I got the message
PS C:\my.repo.name> git add --all
PS C:\my.repo.name> git commit -m "Doing stuff."
PS C:\my.repo.name> git push
...
! [remote rejected] main -> main (TF402455: Pushes to this branch are not permitted; you must use a pull request to update this branch.)
error: failed to push some refs to 'ssh://my.devops.server:22/MyCollection/MyProject/_git/my.repo.name'
Well shit. Now I have my local branch one commit further than my remote and I can’t push them to the remote repository directly. One possibility is to ask the project leader if he would allow me to push to main. Probably he will not. But I found another solution, that worked for me that consists of two steps:
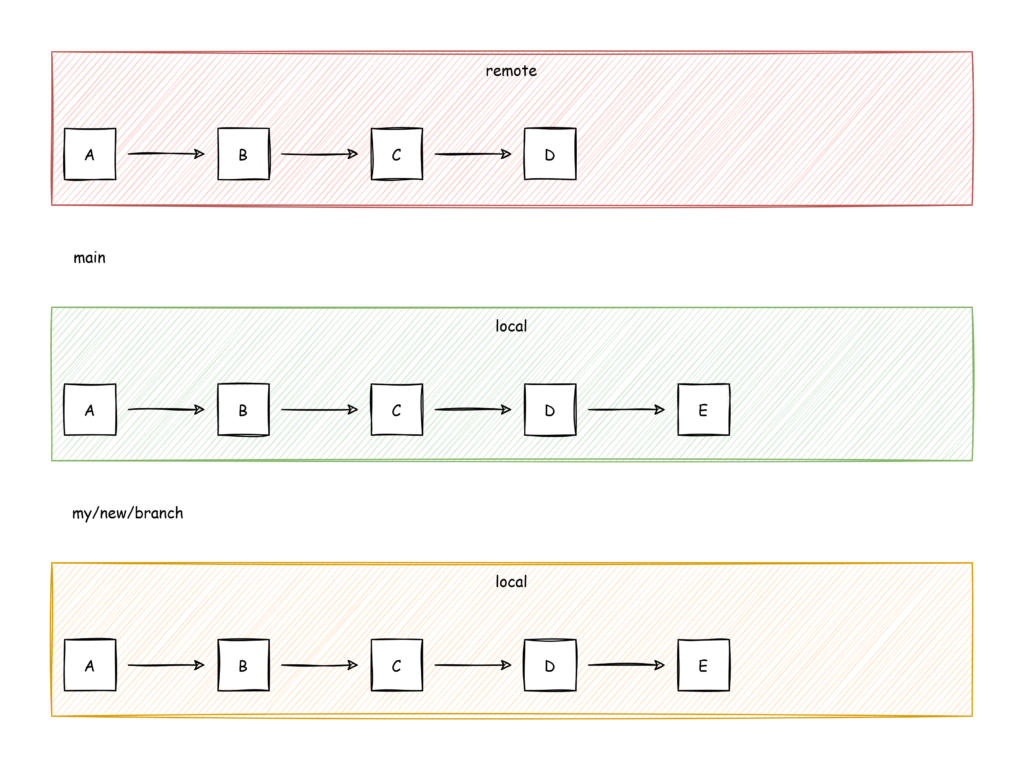
“Export” the unpushable commit to a new branch and push this branch to integrate afterwards via pull|merge request.
Reset the main branch to the same level as the remote branch.
The first one is quite easy. Find the commit id with “git log” and create a new branch:
I have shortened the output. The commit id I used in the example is simply “E” and a real id would look something like “997f11ca98a823aed198df5410f97b769b0b8338”.
With the found id you can create a new branch with
git checkout -b "my/new/branch" E
So basically it looks like this now:
So now you have exported your commit into a pushable branch and you can push it to remote with
git push origin "my/new/branch"
From there on it is the regular procedure of creating a pull request and going through the defined review process to integrate it into “main”.
The last step is to checkout main and reset it to the previous commit. Find the ID with “git log” and then reset it with
git reset --hard D
Now your local branch “main” is back in sync with the remote branch and as soon as the pull|merge request is through you can pull your changes from the remote branch “main” via
I recently had the issue against my on premise Azure DevOps server, that the clone via ssh would fail with the message:
PS C:\Users\goa> git clone ssh://devops.example.com:22/GoaSystems/Java/_git/my.java.project %SERPROFILE%\workspaces\java\my.java.project
Unable to negotiate with 1.2.3.4 port 22: no matching host key type found. Their offer: ssh-rsa
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
The error can look different depending on if you already have a configuration file for SSH or not. But in any case, if a error is thrown, it is likely that the keys are the culprit. Fortunately this is easy to solve. Create the following file
notepad %USERPROFILE%\.ssh\config
and add the following content.
Host devops.example.com
User git
PubkeyAcceptedAlgorithms +ssh-rsa
HostkeyAlgorithms +ssh-rsa
AddressFamily inet
Modify it of course with your specifications (i.e. hostname).
One could ask why “AddressFamily inet”. Well, shame on me, I don’t have IPv6 not properly set up due to a lack of understanding. So now I rely on IPv4 (what this line configures) in order to not have to wait for a timeout every time I’d like to clone something.