“Learning” for me means “practicing”. That’s why I started initializing every single small project with a Git repository, setting up a simple build pipeline and exporting artifacts to a central repository and I do this for Java projects (Gradle, Maven) in the same manner as for .NET projects (dotnet, NuGet). One might ask now: Why not just build the project and copy the output? This method is usable when it is only one project worked on by one developer for example when someone wants to try out some stuff, wants to learn project specifics or it is just a small thing to code (well, even then it is better to setup the tools because if the project grows you have everything ready for a big team). But as soon as there are more developers working on a project it is necessary to use collaboration and automation tools. That’s why I practice setting up the build environments with every new project because then it is routine and not a burden to do.
What is the goal of this article? Let me start with the non-goal: I don’t want to provide a “Click here, then there, then fill this field and click Install.” tutorial. I want to share my experience, provide links to the tools I use and what to do with them and show the outcome. Most of the knowledge needed for this is generic: Setting up a SQL server is not specific to the usage in Azure DevOps and neither is setting up Windows 10. There are a lot of tutorials out there and I don’t have to reinvent the wheel here. I want to show that setting up these tools in the shown order leads to a running DevOps server that can save a lot of time and improve code quality and team collaboration.
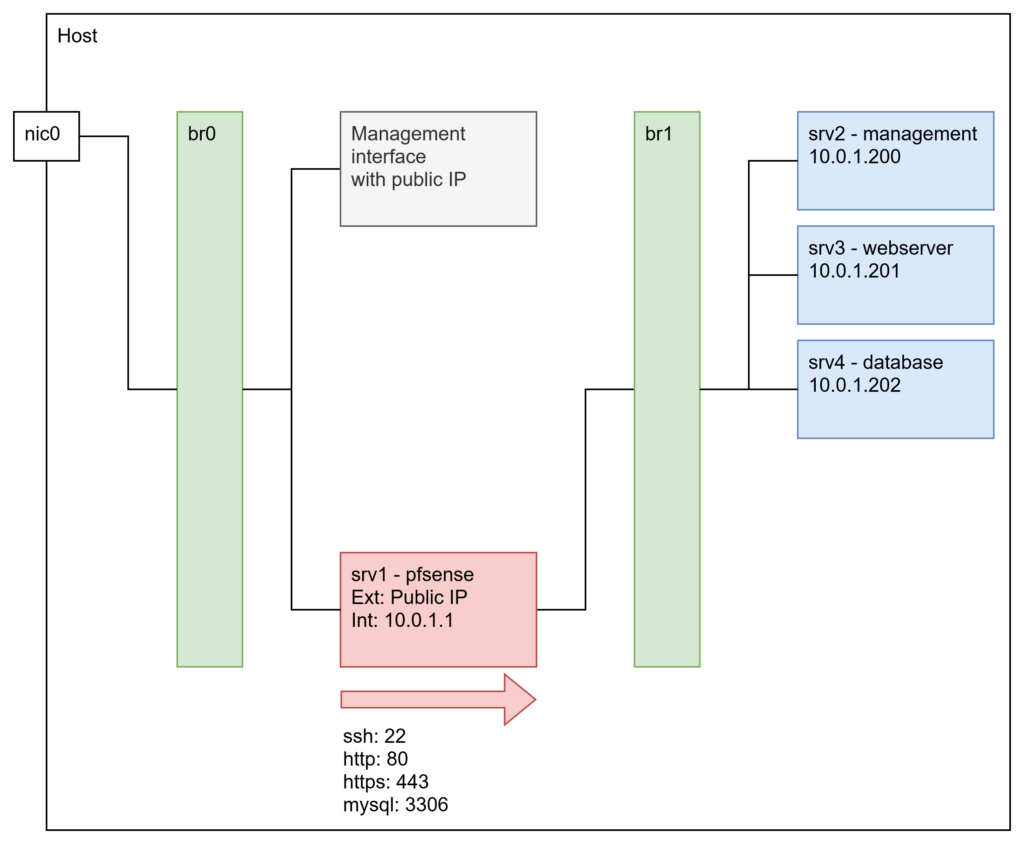
So, what is this setup for? Copying output manually can, as mentioned, be done for one project, maybe two and maybe also up to 10. But then this becomes annoying, confusing and hard to manage. As soon as I work on many projects I just want to commit and push my stuff and the rest is done by the build environment. And that is what this setup is about. Let’s start with the preconditions and prerequisites. I really use a power machine for this task:
- HP Compaq 8200 Elite (initially bought 2012)
- Intel Core i5-2500 quad core CPU (Yes, “Sandy Bridge” generation)
- 16 GB DDR3 memory
- 500GB Crucial SATA-SSD
So, as you can see, you really need top of the line, high performance hardware 😉 No not really. What I want to show here is, that a small, old office computer does the job for learning the stuff.
On the software side I use the bundled operating system and some other tools and programs. Don’t worry, they are all free of charge:
These are all the things you need. Really.
What are the limitations? First of all: You can’t use these tools for big business work loads and environments because they have hardware and software limitations. It’s more than enough to learn, practice and implement small projects but as soon as the requirements rise these limitations prevent you from using the tools in a large environment. The good thing is that the learned skills can be applied directly to big environments because the tools are the same and are handled the same way.
The setup is divided into a few steps to make it easier. I start with a blank machine: No OS, no software and an empty drive:
- Install Windows 10 Pro. You can get it from here. It should already be activated if it was installed beforehand on the computer and the computer is connected to the internet.
- Download and install SQL Server 2019 Express.
It is required for Azure DevOps and can also be used for development databases. I recommend a local setup with “sa” user. - Download and install the latest Azure DevOps setup. I recommend also a local installation with http only. Setting up a SSL PKI and configuring IIS would be to much and does not serve the purpose here.
- Download and install Oracle VirtualBox and the extension pack.
- Setup one or many build agents (Windows agents can be directly set up on the machine, Linux agents can run in VirtualBox instances). Builds are only running on agents, not the DevOps server itself.
As soon as these five steps are done the build server can be used for different project types. Just to name a few:
- Java projects
- Can be build on Windows and Linux build agent.
- Supports different frameworks (JavaEE, Spring, Vaadin, …)
- Supports build systems like Gradle, Maven and Ant.
- .NET core
- Builds all kinds of projects as long as the tools are installed on the build agents.
- Has native support for .NET core tasks.
- Easy usage of private NuGet repository.
- Plain tasks with scripts
- Supports different script languages like PowerShell and Bash.
- Deployment with ssh.
- JavaScript
- Supports common JavaScript frameworks.
I don’t want to go too much into detail here because there are tons of tutorials on the internet and the setup itself is pretty much self explanatory and supports the user with assistants.
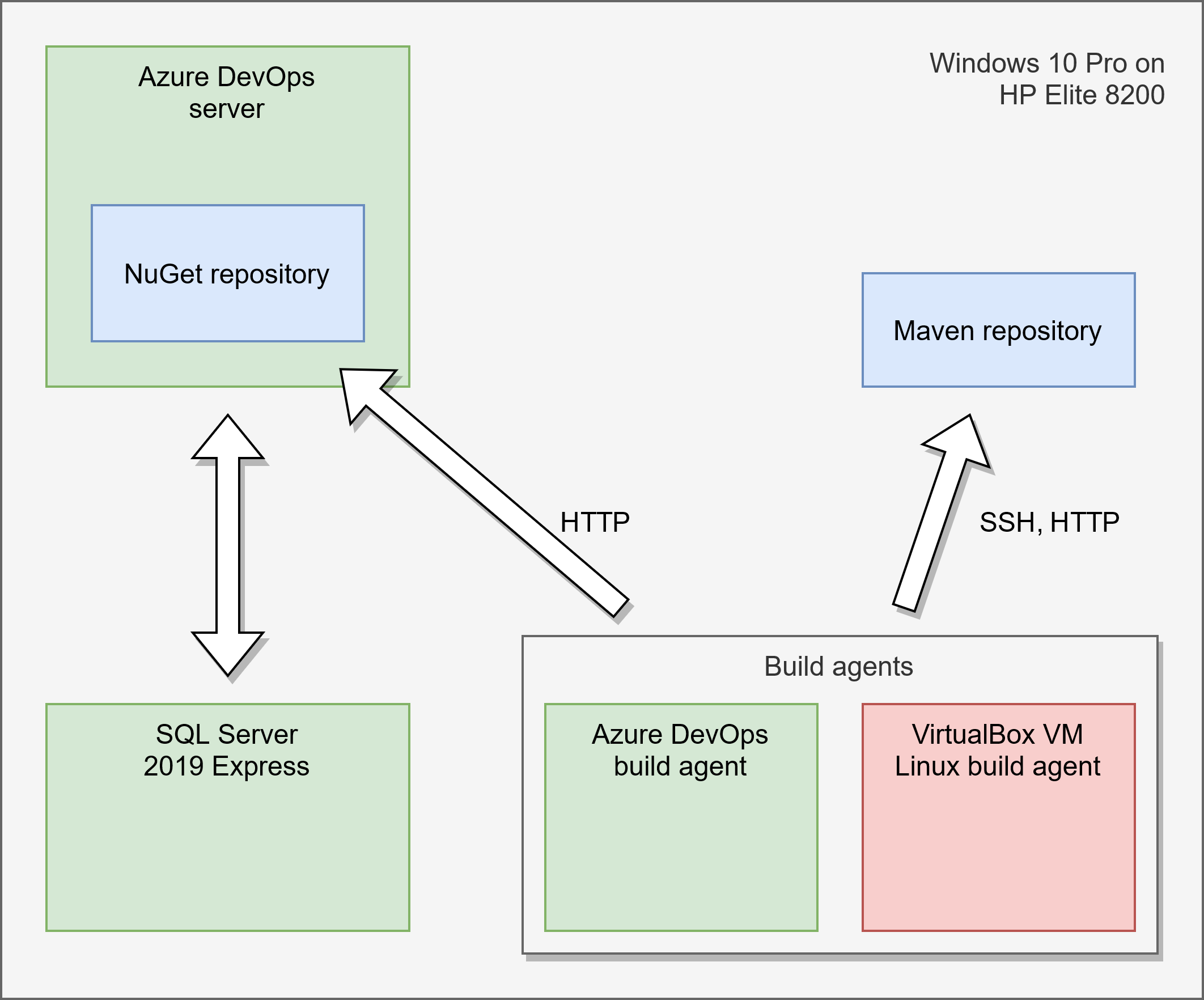
The following diagram shows the architecture. The only difference to my setup is, that my Maven repository is externalized and is not running on the DevOps server. It is optional anyway and used for Java library distribution. So if one is not building Java projects it is not required.